Table of Content
Search Engines Functions – Crawling and Indexing
Search Engines have two major functions
Indexing
Crawling
First of all let’s understand what is spider.
What is Spider – Internet Bot – Web Robot – Bot?
A software application that usually perform certain automated functions, scripts and structural tasks on internet based websites. So a bot visits the worldwide websites, reads all the informational pages from web servers and manage all the accessed material in a structured and managed files system that is called Search Engine Indexing. Crawler are programmed to visit sites that have been submitted by their owners that may be new, old or updated
Crawling and Indexing:
Search engines use the web crawler or sometimes called an automated robots that browses billions of websites to systematically index all the pages regarding all the information contained in them. It means that the all the major search engines like (Google Bing, Yahoo) crawl a website and all of its pages and make their copies in a matter of moments, and store in what’s called “index” which is more likely a massive book of web.
The websites or the internet domains consist on a language based informational page(s), documents, world News , files of a business group, multimedia like pictures in all formats, recreational or educational videos and all the other vital stuff that is crawled by the Spider and indexed in search engine’s databases.
Once the websites are indexed in the web book it is available whenever it is needed by the internet surfers or users. When a user search a query term, the Search Engine carefully looks into its gigantic book page by page, picks out the most relevant, the best one and the more likely page with the search term and show it first on the first page.
Now the question arises in mind, where these databases containing billions of pages are stored?
All the major search engines have developed their own well designed Data Centers to store this informational flow. A data center comprises on heavy equipment, machinery that includes billions of storage hard drives, switches, routers, cables, servers and other computing machines that perform and built relevant results in a fraction of seconds (one to three seconds) against any query given by the users.
Robots.txt and the internal structure of the website plays an important role in website crawling and indexing.
Meta Robots
The Meta Robots Tags are designed to handle the Search engines crawler functionality on per page basis in several ways. It’s all about how they treat the page in a website.
Index/ No-Index
These are often used by the web owners/ web masters whether the page should be crawled or not. If the webmaster use the index option then the page will be crawled and indexed in the search engines databases but if noindex option is opted then that specific page will be excluded from the index. By default search engines has to index all the website but with the use of no index it will not. As the webmaster don’t want to index its payment procedure page so he will chose noindex option.
Follow/nofollow
This option is all about links on the page should be crawled or not, if webmaster apply the nofollow option then the engines will ignore the links on that specific page for discovery and ranking purpose or both. By default the whole website is supposed to have the follow feature.
Example, < META NAME=”ROBOTS” CONTENT =”NOINDEX, NOFOLLOW”>
Noarchive
By default all the major search engines like Google Bing and yahoo maintain the visible copies of all the websites and their pages they have indexed before and make them available to the searchers through cached links so the web owners may use the noachive method to stop the engines from saving the cached copy of the certain page
Nosnippet
Tells the engines to abstain from presenting a descriptive block of text next to the page’s title and URL in the SERP (Search Engine Result Page).
Noodp/Noydir
When used complled the engines do not grab a descriptive snippet of page from the Yahoo or some other directory to display the results in search.
XML Site Map
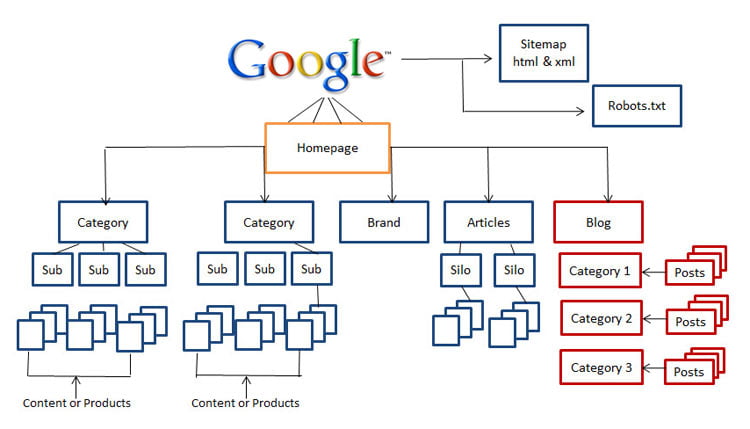
XML sitemap stands for Extensible Markup Language, it is the manual method opted by the web administrator to be crawled by search engine by feeding the hierarchy of website in terms of a list of URLs of pages and the information about when the page was last updated.
Creating and submitting an XML sitemap plays the main role in indexing a website more efficiently in the search engines.
There are many tools available to create the XML sitemaps and some of these are Slick Plan, Dynomapper, WriteMaps and Mindnode etc. However the XML sitemap can be created manually also but we will discuss in details more about xml sitemap later.
Duplicate Content – Canonicalization
Search engine has to crawl and index the entire website with its specific schedule, and it does because its crawler has its responsibility to perform indexing and crawling. But often the search engine becomes confuse about having the same content with multiple copies in its big book “index” which leads to a very tough decision to figure out which of those many pages it should return for a specific given search.
i.e., there are the multiple copies of the same paragraph or the entire page content on more than one locations. It may be on a single website or present on multiple websites. This is a worst practice and is against the S.E guidelines. In terms SEO point of view, it is called duplication or canonicalization.
So for precise results there should be the only single version of the website or a single and unique page content to be indexed in search engines.
Website Speed
Google wants to make the web a faster place and has declared that speedy sites get a small ranking advantage over slower sites.
As we have discussed earlier that there are three major search engines in the web world and all of them has developed new policies regarding speed of the website. Google has clearly declared that the speedy site will have a small advantages over ranking signal than slower websites. But it doesn’t mean that making your webpage speedy is the guarantee to rank higher in the SERP rather it’s a lesser impact definitely.
It is seemed through different conducted surveys that impatient users don’t’ revisit a website which takes longer time to load.
The Site speed may be directly engaged a conversion factor and a dissatisfaction of a customer towards your business. The ideal page load time for a URL differs from 2 to 5 seconds based on the how much content it contains!
So it’s better to speed up your website because Google and other engines definitely appreciate it.
There are many methods to improve the website speed as by enabling compression, enabling browser caching, minifying JavaScript, and CSS etc.
Mobile Friendly Website
The bigger computers changes into small one and the small computers has been changed into tiny infrastructure with the passage of time. This is the new era and the emerging technology of smart mobile phones compelled the search engines to give a rank signal to those sites which are responsive and mobile friendly. If you want an online presence in Google and Bing then you must have a mobile friendly website to compete your competitor otherwise you will have a harder time to be shown in the SERP.
Descriptive URLs
Are you a webmaster and using descriptive URLs, if not, then you will not get a ranking advantage by the Google and the other Search Engines.
By making Descriptive URLs not only increase the user readability but also increase the chances of ranking higher in SERP. So always try to use the descriptive words in posts or page URLs to make a better sense for both the search engines and the humans.
HTTPS / Secure Site
Google would like to see the entire web running HTTPS servers, in order to provide better security to web surfers. To help make this happen, it rewards sites that use HTTPS with a small ranking boost.
Google is more interesting about the user security and gives a ranking signal to those websites which are emphasized with the HTTPS servers. Again I will say that the onsite architecture of the websites is the combination of many factors to rank higher in the engines first page and all play a minor but an important role towards the higher ranking and HTTPs is one of them.